
摘要:本试验依据康奈尔大学净碳水化合物净蛋白体系(CNCPS)和CPM-Dairy配方软件的技术思想,对几种我国常用奶牛饲料原料进行聚类分析。采用近红外分析和实验室分析对4大类[苜蓿干草、干酒糟及其可溶物(DDGS)、玉米粉和玉米青贮],共 1 169个我国常用奶牛饲料样品的 16 类指标进行测定,用聚类分析的方法对样品科学分类。结果表明,用聚类分析的方法,根据不同饲料的特点,分别将苜蓿干草分为 12 类、DDGS 分为 10 类、玉米粉分为 5 类、玉米青贮分为6 类。综合得出,聚类分析的方法得出结果符合CPM- Dairy饲料数据库要求,且可信度高。
CPM- Dairy 是基于康奈尔净碳水化合-蛋白质体系(CNCPS)研究开发的目前世界上最先进的奶牛配方软件。它在饲粮配方设计中,考虑了动物、环境与管理、饲料在瘤胃内的消化与流通速率等因素,充分反映了动物类型、生产水平、环境、饲粮组成及管理间的交互作用,体现了软件的动态性和精准性。聚类分析是根据研究对象的特征对其进行分类的多元技术的总称,是应用最广泛的分类技术。聚类分析在生物领域的应用主要集中在对动植物和基因进行分类,获取对种群固有结构的认识。此方法可用来对变量进行分类,称为R型聚类,也可用以对案例进行分类,称为Q型聚类。多种分类聚类法中,应用最广泛的是层次聚类和迭代聚类。聚类分析要求所选择变量之间不可高度相关,否则相当于对这些变量进行了加权。分析结果中,同一类个体应具有高度同质性,不同类之间应具有高度异质性。
CPM- Dairy 配方软件通过对大量饲料及试验数据的回归分析,集奶牛饲粮配方的预测、评价和优化功能于一体。研究表明,CNCPS 体系对90% 以上变量的预测结果与实际生产的偏差只有1.3%。Tedeschi 等使用 CPM- Dairy 3.0 对228 头泌乳奶牛的实测与模型预测产奶量进行线性回归,结果表明,该模型对79.8%的变量做出了正确预测,整合相关系数高达0.997,预测的均方根误差为 5.14 kg /d,且 87.3% 的均方根误差源于随机误差,说明对高产奶牛的产奶量预测中,系统误差很小。在美国,利用该体系使奶牛平均单产在 10 年间(1989—1998 年)提高了 20%。
目前,CPM- Dairy 配方软件在全世界 42 个国家得到了广泛的应用。通过不同样品的信息特征比较,聚类分析结果可表明样品间的一致程度,进而确定样品的归属关系。由于生长环境、收割期、加工方法及贮存时间不同,即便同一种饲料原料其营养成分差异也较大。因此,需要利用聚类分析方法对饲料进行科学有效的分类和汇总。目前,我国奶牛应用的饲料种类与品质上与美国存在较大差异,已有的饲料成分表及营养价值表也存在一定的局限性,主要表现在奶牛常用饲料营养成分信息过时、不完善、分类不准确等,给应用 CPM- Dairy 配方软件配制奶牛高效饲粮造成了不便。本研究旨在依据 CNCPS 和 CPM- Dairy 配方软件的技术思想,收集测定部分我国常用奶牛饲料原料的营养成分,并用聚类分析法对饲粮样品进行科学分类,为建立奶牛精准营养管理软件奠定基础。
1 材料与方法
1.1 饲料样品收集
对我国现有各大型牛场常用原料进行调查研究,并与原 CPM- Dairy 饲料数据库信息进行对比分析,寻找并收集在原数据库中没有体现及国内外成分差异较大的饲料品种,分别为苜蓿干草(442 个)、干酒糟及其可溶物(DDGS,143 个)、玉米粉(263个)、玉米青贮(321 个)(表 1)。原料收集后尽快于 65 ℃烘干后装袋保存,在测定前统一粉碎直径为 0.5 mm 微粒。
1.2 指标测定及方法
CPM- Dairy 配方软件从预测到优化均以饲料各指标的表观数据为基础,因此,需测定样品中干物质(DM)、有机物(OM)、粗蛋白质(CP)、粗脂肪(EE)、中性洗涤纤维(NDF)、酸性洗涤纤维(ADF)、酸性洗涤木质素(ADL)、粗灰分(ash)、非纤维性碳水化合物(NFC)、酸性洗涤不溶性蛋白质(ADIP)、中性洗涤不溶性蛋白质(NDIP)、可溶性蛋白质(SP)、非蛋白氮(NPN)、淀粉、脂肪酸、微量元素(铁、锌、铜、锰、硒、钴、碘)和常量元素(钙、磷、镁、钾、钠、氯)的含量。测定方法:苜蓿干草、玉米粉和玉米青贮饲料样品送至华夏牧业有限公司进行近红外扫描,DDGS 在西北农林科技大学动物科技学院实验室分析。其中,DM、OM、EE、CP、NDF、ADF、ADL、NFC、ash 含量的测定参考 AOAC,ADIP、NDIP、SP、NPN 含量的测定参考 Fortina 等、Krishnamoorthy 等和 Licita 等的方法,淀粉含量采用试剂盒(爱尔兰 Megazyme)测定,脂肪酸含量的测定参考 Qi 等的方法,常量元素、微量元素含量采用原子吸收法测定。
1. 3 聚类分析
本研究严格遵循变量与聚类分析的研究目标密切相关,不同研究对象上的值有明显差异,变量间不可高度相关的原则,采用R型聚类对变量进行筛选,并根据生产实践和软件需要对变量进行最后确定。选定聚类变量后,通过 Q 型聚类对研究对象进行分类。层次聚类是多种 Q 型聚类分析中应用最广泛的聚类方法,其聚类过程可用一个树状图表示出来,根据树状结构图进行不同的分类处理。
1.3.1 数据整理
以苜蓿干草(442 个样品)为例,简述在 SPSS17.0 中进行聚类分析的操作方法。将苜蓿干草各营养成分的数值输入软件中(图 1)。

1.3.2 聚类类型及方法的选择
激活“分析(analysis)”菜单选“分类(classi-fy)”中的“层次聚类(hierarchical cluster)”项,从弹出对话框左侧的变量列表中选 ash、 ADL、 EE、CP、 ADF、 NDF、 NFC(根据经验选用常量指标),点击按钮使之进入“变量(variables)”框;在“聚类(cluster)”处选择聚类类型,其中“个案(cases)”表示观察对象聚类, variables 表示变量聚类。本例是对变量聚类,因此,选择 variables(图 2)。
点击“图表(plots)”钮,选择“树形图(dendro-gram)”项(图 3 - a),要求系统输出聚类结果的树状关系图,点击“继续(continue)”钮返回。点击“统计(statistics)”钮,弹出“层次聚类分析(hierar-chical clusteranalysis)”,选择“相似矩阵(proximitymatrix)” (图 3 - b),要求结果中显示距离矩阵,点击 continue 钮返回 hierarchical cluster analysis 对话框。



在对变量的R型聚类中,以“皮尔逊相关关系(Pearson correlation)”作为聚类方法。为确保聚类结果的可信性,需选用不同的聚类方法反复聚类,取共同部分来去除随机因素的影响。在本例中,分别选用组间聚类和质心聚类(centroid cluste-ring),如图 4 所示。点击 continue 钮返回 hierar-chical clusteranalysis 对话框,点击“确定(OK)”钮即完成分析。
2 结果
2.1 饲料样品指标聚类结果
苜蓿干草主要指标聚类树状图见图 5。从 2种聚类方法得到的树状图可以看出,聚类方法可信。由于确定分类数的问题迄今尚无统一定论,实际操作中,需根据经验而定,本例在与原数据库比较的基础上,选择了 CP 和 NDF 作为分类主要指标。
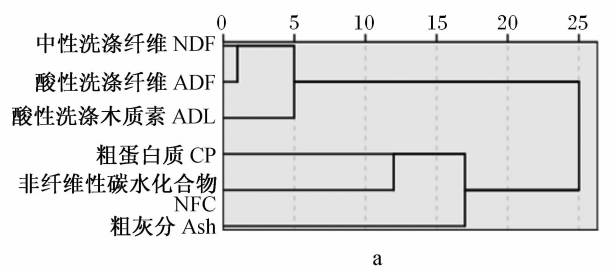
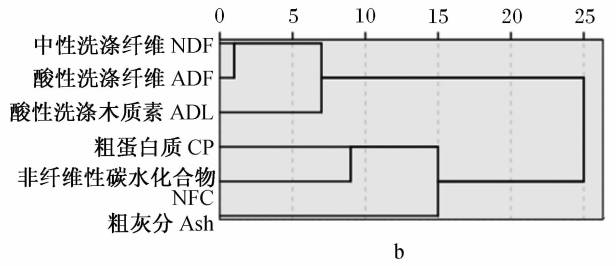
2.2 饲料样品聚类结果
在对样品的聚类中,本例中选用 centroid clus-tering 方法和平方欧几里德距离(squared Euclideandistance),先根据样品的 CP 聚类,将样品分为6 大类,将归到每 1 类的样品 CP 值求平均。之后对每个蛋白质类的样品根据 NDF 指标再重新聚类,对树状图(略)结果进行整理,苜蓿干草的 442 个样品共分为 12 类,将每类中的样品指标整合后结果见表 1。
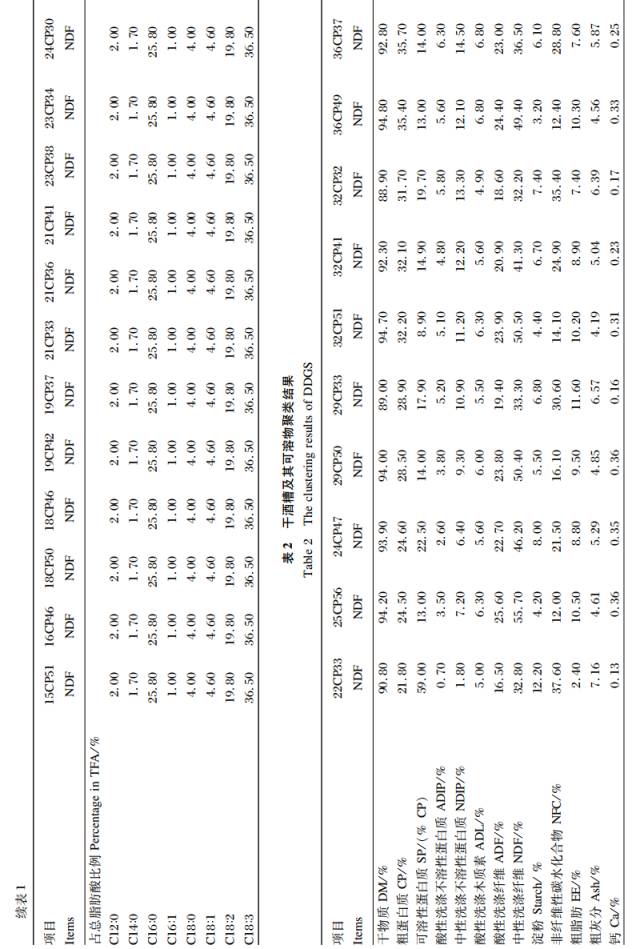
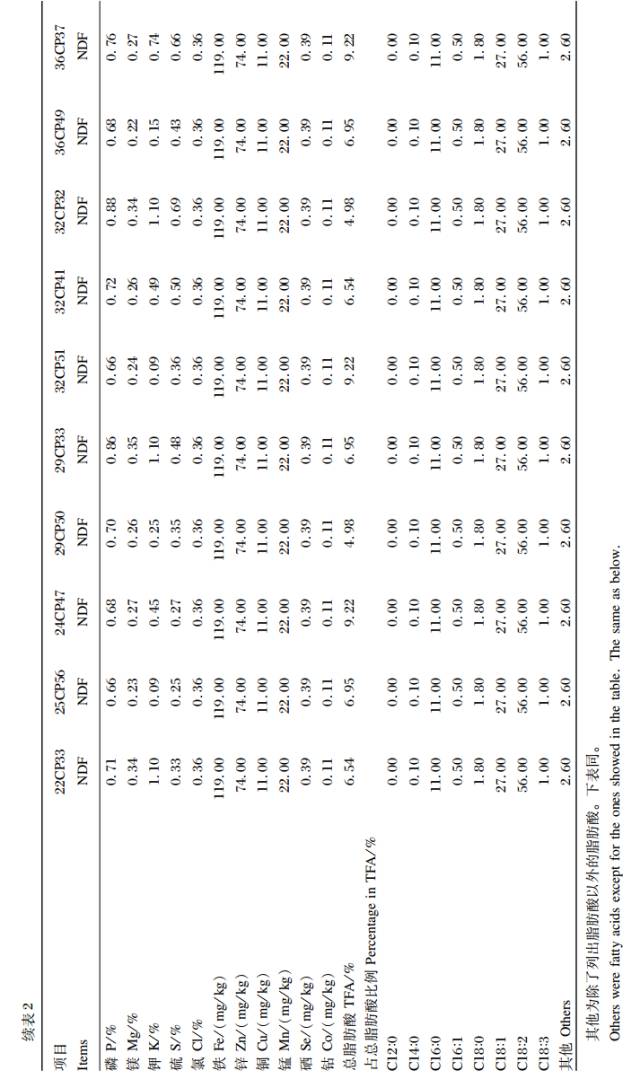
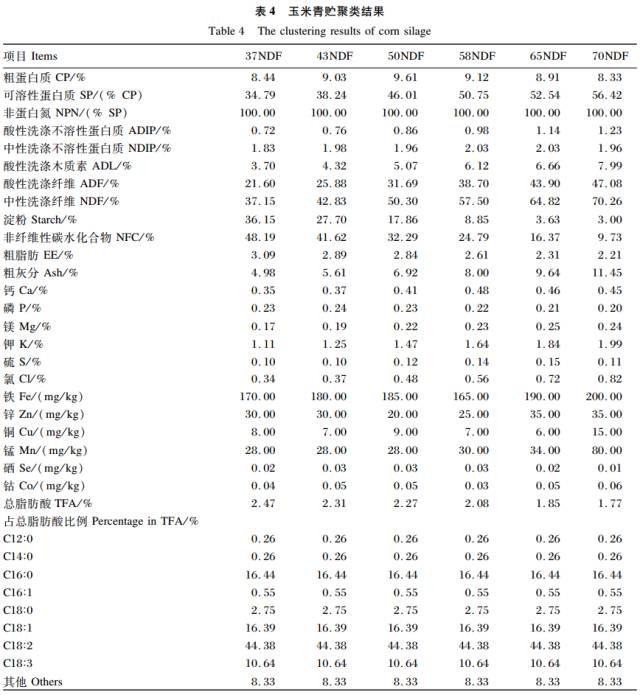
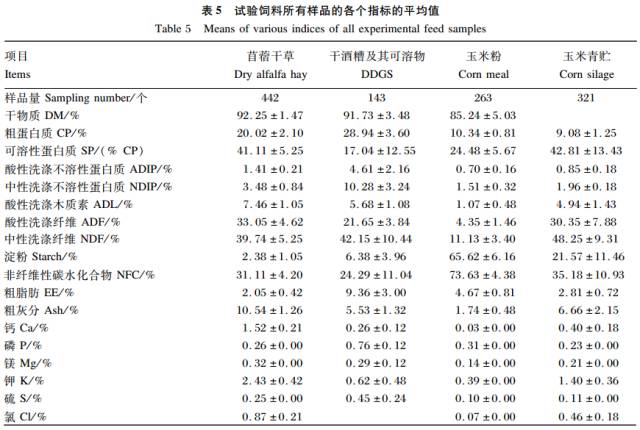
同理,DDGS 样品聚类分析的结果是将 CP 和NDF 作为主要指标,在此基础上,最终样品分成了10 大类,结果见表 2。玉米粉的聚类结果是将淀粉作为主要指标,样品最后分为了 5 大类,结果见表 3。根据聚类分析结果,玉米青贮的主要聚类指标选定为 NDF,样品被分成了6 大类,结果见表 4。表 5 为试验饲料所有样品的各个指标的平均值。


3 讨论
聚类分析是数据挖掘中的一个重要研究领域,在生物领域的应用主要集中在对动植物种群固有结构的认识,受到广泛关注。聚类分析中,并不是加入的变量越多,得到的结果越客观。有时,加入一两个不合适的变量就会使得分类结果大相径庭。而且,不加鉴别地使用高度相关的变量相当于给这些变量进行了加权。因此,聚类分析应该只根据在研究对象上有显著差别的变量进行分类,而研究者需要对聚类结果不断进行检验,剔除在不同类之间没有显著差别的变量。此外,为使数据库的界面更加友好,使用更便捷,CPM- Dairy 配方软件要求先对每 1 种饲料原料选出 1 个或几个最具代表性的指标,再根据选定指标对样品进一步分类。本研究对饲料原料分类指标的确定是由聚类分析的结果及饲料本身特性共同决定。
本研究在 CNCPS 的理论指导下,收集、分析了全国范围内部分我国常用奶牛饲料原料的营养成分,使用聚类分析的方法,按照 CPM- Dairy 的要求对样品科学分类,符合饲料分类的基本方法。聚类分析法只对差异较大且没有高度相关的研究对象分类才有意义。苜蓿干草的聚类中,首先选用R型(横向)聚类对指标进行分类并选择。苜蓿干草 CP 和 NDF 含量相关性较低(图 5);而苜蓿干草的 CP 含量在 14.87%~24.14% 之间, NDF含量在 29.82% ~ 50.63% 范围内变化,同一指标同种样品间差异较大。而且,Minson 和 Sheaffer等的研究结果表明,CP 和 NDF 含量是最能反映粗饲料特征的指标。因此,将 CP 和 NDF 含量作为苜蓿干草的主要分类指标,这与 Fox 等的分类依据相同。在对饲料样本进行 Q 型(纵向)聚类时,采用层次聚类的思想,将样品共分成了 12类。Fox 等建立的 CNCPS 5.0 /CPM-Dairy 3.0饲料数据库中,苜蓿干草的 CP 变化范围为17.00%~25.00% (分别为17%、20% 和25% ),NDF 范围为 32.00%~46.00% (分别为 32% 、35%、37% 、40% 、43% 和 46% )。本研究中,苜蓿干草不同分类间 CP 含量相差约 1 个百分点,NDF含量相差 2~ 4 个百分点,符合 CPM- Dairy 数据库的要求。
DDGS、玉米粉和玉米青贮的聚类思想及方法同苜蓿干草。Kim 等研究表明,DDGS 是玉米提取酒精后的副产物,主要成分为粗纤维、CP 和油脂。国内 DDGS 样品的 CP 含量变化范围为21.8%~35.7%,NDF 含量为 32.2%~55.7%,样品间差异较大。所以本研究将 CP 和 NDF 含量作为 DDGS 的主要分类指标,这与 Singh 等评价 DDGS 的依据为 CP 和 NDF 含量为主要指标相同。玉米粉和玉米青贮分别以淀粉和 NDF 含量为分类指标,是因为对玉米粉品质影响最大的成分是淀粉,且本研究中玉米粉样品的淀粉变化范围较大(51.93% ~74.91% );玉米青贮 NDF 含量的变化范围较大(37.2%~70.3% ),而 CP 含量的变化变化差异不明显(8.3%~9.6% )。对样品分类后,同种原料类与类之间的差值均符合 CPM-Dairy 原料数据库要求。苜蓿干草的 CP 和 NDF含量,DDGS 的 CP 和 NDF 含量,玉米粉的淀粉以及玉米青贮的 NDF 含量变异均相对较大,说明本研究中分类的依据合理。由表 6 可知,各类饲料的 SP 均变异很大,可能是由于饲料中 SP 大部分是 NPN,这与靳玲品等的研究结果一致。
比较本研究结果和 CPM- Dairy 原料数据库数据发现,我国常用奶牛饲料原料与该数据库数据存在很大差异。以玉米青贮为例,国外的玉米青贮 NDF 含量变化范围是在40%~50%,国内玉米青贮 NDF 的变化范围是在40%~70%之间。因此,不断完善并建立我国常用奶牛饲料数据库,对建立奶牛精准营养管理软件及其应用至关重要。
4 结论
用聚类分析的方法,根据不同饲料的特点,分别将苜蓿干草分为 12 类、DDGS 分为 10 类、玉米粉分为 5 类和玉米青贮分为 6 类,其结果符合CPM- Dairy 原料数据库要求。
(转自:动物营养学报)
